
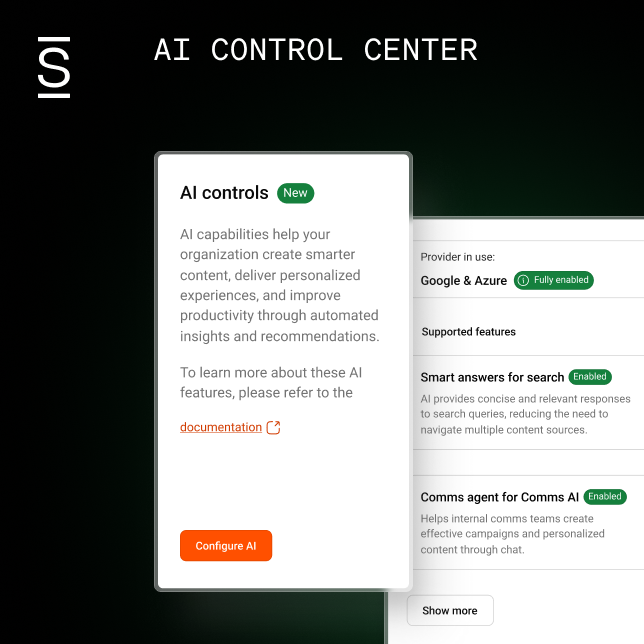


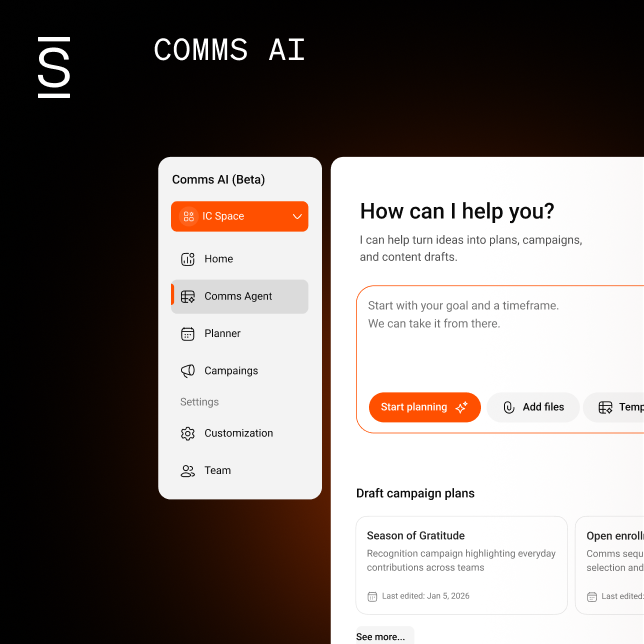


You’re searching for a particular document across your company’s enterprise systems. You enter the exact terms from the title into search. It returns nothing — or floods you with irrelevant results — slowing down decisions and productivity.
The evolution of Simpplr enterprise search: from keywords to self-learning
The evolution of Simpplr enterprise search: from keywords to self-learning
Table of contents
- 1 The keyword era and why matching wasn't enough
- 2 Semantic search is table stakes, not differentiation
- 3 Hybrid search balances precision and meaning
- 4 Learning-to-rank turns search into a self-learning system
- 5 What this evolution means for your organization
- 6 Experience Simpplr’s enterprise search
This isn’t just annoying — it’s expensive. Every failed enterprise search is time wasted, decisions delayed, or worse, employees making choices based on outdated information they found instead of what they needed.
Enterprise search has evolved dramatically over the past decade. Many systems now understand natural language. Fewer understand organizational context. Even fewer improve automatically based on how your employees actually work. That gap matters more than most IT leaders realize.
This is the story of how Simpplr’s enterprise search moved from basic keyword matching to systems that learn from organizational behavior. Understanding this evolution to true enterprise search helps you evaluate what your organization needs and what vendors are really offering.

The keyword era and why matching wasn’t enough
Let’s start with where most search technology began — and where some platforms still are. Keyword matching was functional for its time, but understanding its limitations shows why the evolution had to happen. More importantly, keyword matching is no longer a competitive advantage. It’s the minimum requirement for search to function at all.
How keyword search worked
Early enterprise search had no concept of meaning. It was purely mechanical.
Keyword-based search followed straightforward logic:
- Exact term matching: Documents had to contain the precise words you typed
- Manual weighting: IT teams configured which fields (title, body, metadata) mattered most
- Handcrafted heuristics: Rules were built one at a time to handle specific cases
The system understood characters, not meaning. Result ranking became a balancing act of boosts, biases, and endless tuning. You could spend days fixing one edge case only to watch an unrelated policy disappear to page three.
When it worked, when it failed
Keyword search rewarded exact phrasing and punished everything else. Priya searches “expense reimbursement form” and finds the exact document because those words appear in the title.
Daniel searches “how do I get my money back for travel costs” and gets buried under irrelevant content. The intent behind both queries was identical. To a keyword engine, these were two different universes.
As the organization scales, this friction adds up. Minutes spent scrolling through irrelevant results turn into hours of lost productivity every week.

Semantic search is table stakes, not differentiation
Semantic search changed the equation. Large language models trained on vast language patterns could finally understand that “vacation days” and “PTO policy” mean the same thing. Search could interpret intent, not just match words. Natural language queries actually worked for the first time.
Today, these capabilities define baseline competence, not leadership. The real question is what a platform does beyond that baseline.
What semantic search unlocked
Semantic search didn’t just improve results. It changed what was possible to ask in the first place.
Modern semantic search handles several types of query understanding automatically:
- Location detection: When Susan in India searches “employee benefits,” the system prioritizes results for employee benefits in India, not those that apply to U.S.-based employees.
- Acronym expansion: When someone searches “PTO,” the system searches for both “PTO” and “paid time off.” It can even be tuned for organization-specific jargon.
- Recency detection: When someone queries “25.10 release docs,” it assigns a strong boost to documents published around that release date.
- Intent detection: The system determines whether users want documents, people, or organizational insights. Searching “Who is Ravi” returns a person’s profile. Searching “holiday calendar” returns a list of holidays.
- Unified access across sources: Modern semantic search indexes external repositories — Confluence, Google Drive, SharePoint — through the same pipeline as internal content.
Semantic search also changes how systems process documents. Enterprise policy manuals and technical guides can run 30 to 50 pages. Encoding that in a single pass doesn’t work — important details get lost or diluted.
The solution is semantic chunking: breaking documents into smaller units that each represent a coherent idea. Each chunk is independently embedded and indexed while staying connected to the source.
But chunking quality varies across platforms. A one-size-fits-all approach — splitting at fixed intervals regardless of structure — produces fragments that lose context.
Effective chunking adapts to the document type and its source. A legal policy needs different treatment than a technical guide. The process respects internal structure and preserves how ideas flow within the content. That quality directly affects search precision, the usefulness of result excerpts, and the accuracy of any AI-generated answers.
The enterprise-specific challenge
Here’s where semantic search hits a wall. Consumer search optimizes for relevant results. Enterprise search needs the right result — the official policy, not an outdated version. The authoritative source, not someone’s reference notes.
Semantic search treats all similar documents equally. If five documents discuss “benefits enrollment,” semantic search returns all five based on similarity scores. But employees need the current HR policy, not last year’s draft or a team summary document.
Where semantic search falls short
For all its advances, semantic search still can’t solve certain critical problems that matter in enterprise environments.
Three critical gaps remain:
- Treats all semantically similar documents as equally valid: There’s no understanding of which document is official within your organization.
- Struggles with exact matches: Employee IDs, phone numbers, specific codes, and short queries expecting title matches don’t work reliably.
- Lacks awareness of organizational trust: Rankings remain unchanged even when usage patterns clearly favor one document.
Semantic search alone is powerful but incomplete. It can understand what users mean. It can’t handle the messy reality of how enterprise data actually exists — or deliver precision when users need something specific.

Hybrid search balances precision and meaning
Most vendors stop at semantic search or pick one approach over the other. Hybrid search accepts a fundamental truth: Enterprise environments are messy, and employees search in different ways for different things.
Sometimes they need semantic understanding. Sometimes they need exact matches. Often they need both simultaneously.
Why enterprises can’t choose just one approach
The reality of enterprise data makes a single approach insufficient. Organizations have PDFs scattered across SharePoint with inconsistent naming. Multiple documents labeled “final” from different years. Policies pulled from Confluence, Google Drive, Jira, and other connectors. Natural language queries mixed with searches for specific IDs, emails, or codes.
You can’t optimize for just semantic understanding or just keyword precision. You need both working together.
How hybrid search works
Instead of choosing between approaches, hybrid search uses both at once.
It runs two retrieval systems simultaneously and combines their results:
- Semantic understanding handles natural language queries and concept matching
- Keyword precision handles exact matches, IDs, phone numbers, and codes
Both scoring systems run at the same time, and results are fused based on what the query actually needs. The advantage: employees don’t need to know the “right way” to search. They can type a full question, a keyword, an employee ID, or an email address — and the system adapts.
Static ranking is the remaining limitation
This is where most search implementations plateau. The scores are good. The documents are relevant. But the ranking doesn’t reflect what employees actually do.
Consider this: Four documents about “employee benefits” are semantically similar and contain relevant keywords. Hybrid search returns all four with similar scores. But users consistently click the seventh result because it’s the official HR source everyone trusts.
In an enterprise search environment, similarity scores — semantic or keyword — can’t learn which documents employees actually rely on. They have no awareness of connector trust, organizational freshness needs, or real usage patterns. If users repeatedly choose a result ranked at the seventh or eighth position, shouldn’t the system learn from that?
Hybrid search gives you a strong set of relevant documents. But it can’t learn which ones matter most in your organization. That requires a different approach entirely.

Learning-to-rank turns search into a self-learning system
Learning-to-rank (LTR) is an adaptive relevance layer that learns from user interactions, organizational behavior, and contextual signals to continuously optimize search results across the enterprise.
Semantic and hybrid search rank results by similarity scores. LTR learns from which results employees engage with. It tracks which sources are trusted for specific query types and how organizational context shapes relevance. The result is search that adapts to your organization’s specific needs over time.
LTR changes the question from “which documents are semantically relevant?” to “which result is most useful for this employee, in this organization, right now?”
Why LTR became necessary
The fundamental shift: Retrieval is table stakes. Relevance is what matters.
Semantic and hybrid search retrieve relevant documents. But “relevant” doesn’t mean “useful.” In enterprise environments, employees need the trusted source, not just any source. The current policy, not the archived version. The document that answers their question based on their role and location.
Unlike web search, enterprise intranets don’t optimize for popularity at massive scale. They optimize for trust, accuracy, and organizational context.
This requires learning from signals that only exist within organizations. Which results do employees click? Which do they skip despite high similarity scores? Which sources are authoritative for specific content types? How does recency apply differently for project updates versus benefits policies? These are organizational signals shaped by role, location, and department. Similarity scores can’t capture them.
The librarian analogy
The technical distinctions matter, but a simpler frame helps.
Think of search evolution this way:
- Keyword search: A librarian who searches strictly by catalog labels. If the wording doesn’t match exactly, they shrug.
- Semantic search: A librarian who understands what topic you’re interested in, even if you describe it loosely.
- Hybrid search: A librarian who checks both the catalog system and their understanding of topics — balancing precision with meaning.
- Learning-to-rank: An experienced librarian who pays attention to which books get checked out. Over time, they place the most helpful ones at the front desk.
How LTR works at Simpplr
Simpplr trained an LTR model on real organizational behavior, drawing on hundreds of features beyond query-document similarity.
These elements include:
- User engagement patterns: Captures more than clicks, reflecting whether employees stay with a result, return to it, and use it successfully
- Content freshness and reliability: Accounts for how current and dependable content is within the organization’s specific context
- Source and connector trust: Reflects which systems are authoritative for different query types, such as HR policies or engineering documentation
- Semantic and keyword relevance: Provides an initial relevance baseline rather than determining rankings on its own
The model continuously learns. When employees consistently choose one result over another, the system adapts. When certain enterprise sources prove more reliable for specific query types, they rise in rankings. When content becomes stale relative to organizational needs, the system recognizes it.
The outcome that matters
The technical architecture matters less than what it produces.
With LTR:
- Results improve as your organization uses search
- Trusted, current content rises based on actual usage, not assumptions
- Search becomes a self-learning system that understands your organization better over time
Many platforms can retrieve information. Simpplr’s enterprise search improves the quality of results by learning which information employees actually rely on — and continuously elevating the most trusted and useful content.

What this evolution means for your organization
The journey from “Did the words match?” to “Was this useful for this employee?” represents a fundamental shift in enterprise search.
Each evolution solved real problems. Keyword search made information findable through exact matches. Semantic search made natural language queries work. Hybrid search balanced precision and understanding. Learning-to-rank made search adapt to how users engage with the results.
When evaluating enterprise search today, the questions change. Don’t ask, “Can it understand natural language?” That’s the baseline. Ask, “Will it learn from how our employees actually work? Will it get smarter as our organization uses it? Can it distinguish between semantically similar documents based on which ones our teams trust?”
Fewer platforms can learn from your organization’s behavior to surface the relevant information over time. That difference compounds — every search teaches the system what matters in your specific organizational context.

Experience Simpplr’s enterprise search
Simpplr’s enterprise search solution incorporates all four layers of this evolution — keyword precision, semantic understanding, hybrid fusion, and LTR.
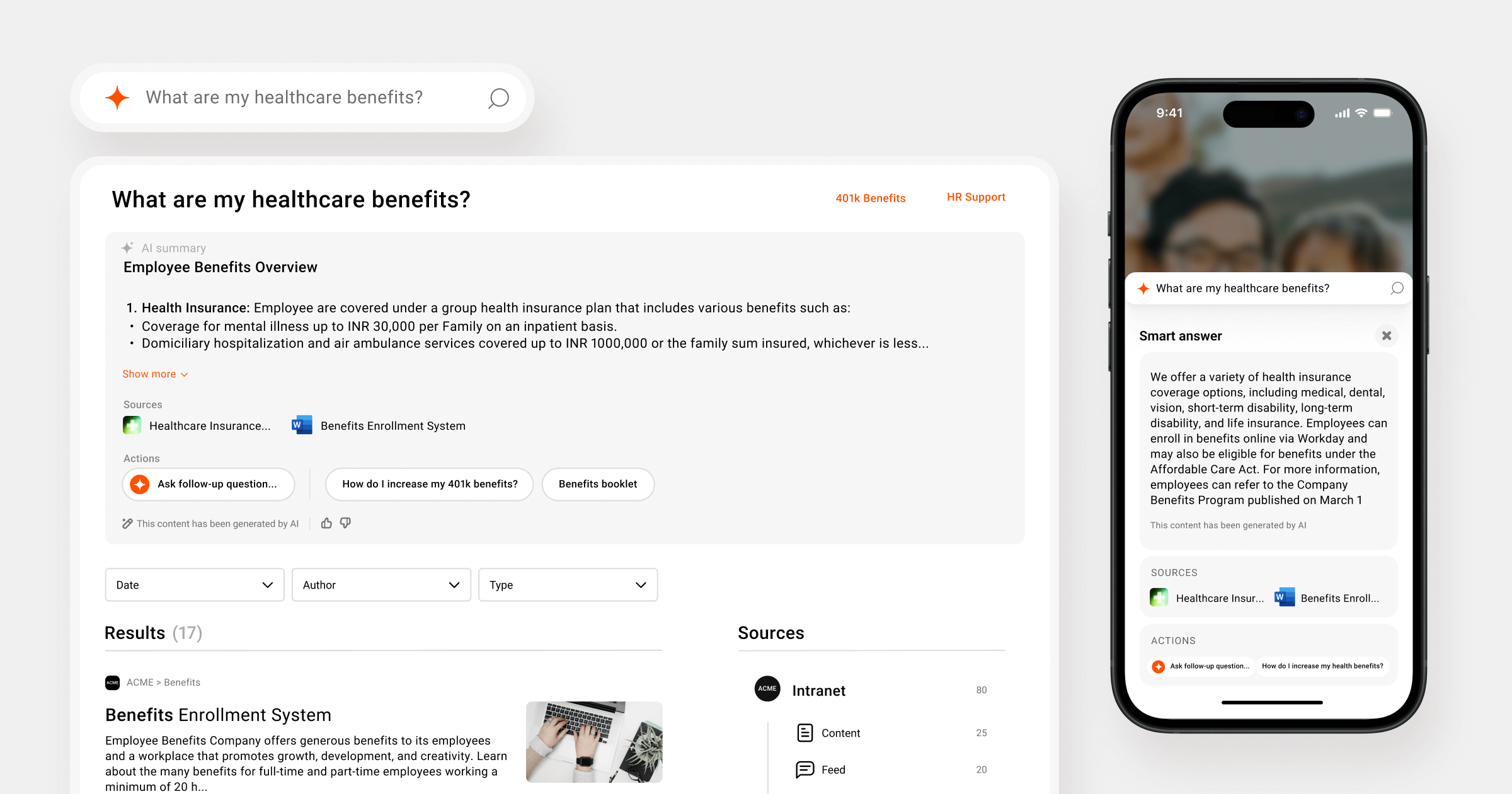
The difference is in what happens over time. Simpplr’s enterprise search doesn’t just retrieve relevant documents. It learns which information your employees rely on, which sources they trust, and how your organization’s needs evolve. Every search makes the next one smarter.
Ready to find out how Simpplr enterprise search works in your organizational context? Request a demo today.
Watch a 5-minute demo
See how the Simpplr employee experience platform connects, engages and empowers your workforce.
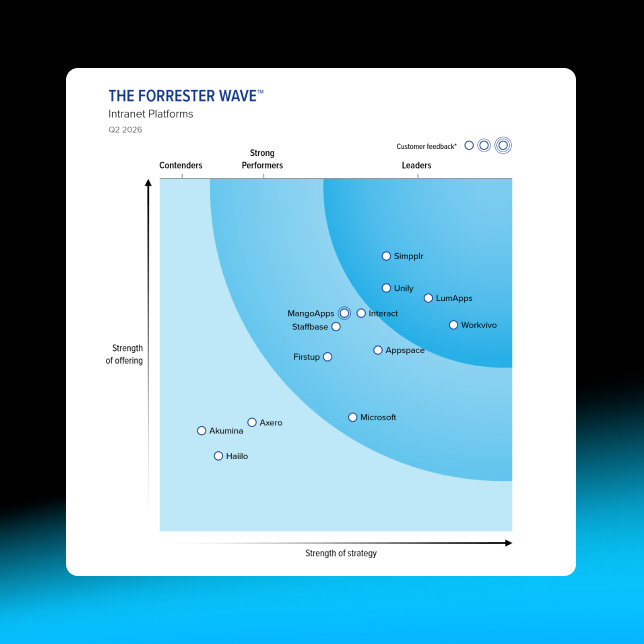
- #1 Leader in the Gartner Magic Quadrant™
- 90%+ Employee adoption rate